Auteur/autrice : admindjpc
Mai 2026
21 Mai 2026 Amphi 12 (bâtiment B)
Orateurs : Benjamin Hellouin de Menibus (Univ Paris Saclay) & Victor Lutfalla (LIS, équipe CaNa)
Sujet : reconnaissance de pavages par automates
Programme :
14h : Introduction aux pavage et sous-shifts en dimension 1 (Amphi 12)
14h45 : pause café (Salle 3.01B)
15h15: Reconnaissance des pavages en dimension 2 (Amphi 12)
Résumé : [à venir]
Décembre 2024
Jeudi 19 décembre 2024
9h30
Speaker : Daniil Kozhemiachenko (LIS, équipe LIRICA)
Title : Logiques paraconsistantes pour le raisonnement sur l’incertitude
Abstract: Pour etre paraconsistante, une logique doit invalider le principe de l’explosion, soit il doivent exister deux formules A et B telles que A&¬A n’implique pas B. Dans cet expose, nous discutons une logique simple paraconsistante de Belnap et Dunn (BD) ainsi que ses augmentations modales et considerons leurs applications au raisonnement sur l’incertitude. Nous traiterons la notion d’incertitude de deux manieres: d’un cote comme une mesure d’incertitude exprimee par une probabilite ou fonction de croyance; d’autre cote comme elle apparait dans les phrases du langage courant telles que «je crois, que…», «je pense, que…», etc. Pour chacun des deux approches a l’incertitude nous proposons sa formalisation a l’aide de BD.
10h15
Speaker : Benjamin Bergougnoux (LIS, équipe COALA)
Title : Neighborhood operator logics: efficient model checking in terms of width parameters
Abstract: In this talk, I will introduce the family of neighborhood operator (NEO) logics which are extensions of existential MSO with predicates for querying neighborhoods of vertex sets. NEO logics have interesting modeling powers and nice algorithmic applications for several width parameters such as tree-width. NEO logics capture many important graphs problems such as Independent Set, Dominating Set and many of their variants. Moreover, some NEO logics capture CNF-SAT via the signed incidence graphs! We can capture more problems by considering various extensions of NEO logics. For example, we can capture problems with global constraints such as Hamiltonian Cycle via the extension of NEO logics with predicates for checking the connectivity/acyclicity of vertex sets.
In terms of algorithmic applications, NEO logics seem to be the perfect candidates for capturing many problems that can be solved efficiently in terms of width parameters.
This is suggested by the following three results:
- For tree-width, the most powerful NEO logics can be model checked in single exponential time in terms of tree-width as implied by a result of Michal Pilipczuk [MFCS 2011].
- Jan Dreier, Lars Jaffke and I proved that, for an extension of one NEO logic, we can obtain an efficient model-checking algorithm in terms of several width parameters more general than tree-width such as clique-width, rank-width and mim-width [SODA 2023].
- Vera Checkan, Giannos Stamoulis and I are currently proving that the most powerful NEO logic can be solved in single exponential time and polynomial space for tree-depth: the shallow restriction of tree-width. This last result could be interesting in practice where space usage is crucial.
I will present these three results after a friendly introduction on width parameters.
Pause Cafe : 11h00 — 11h30
11h30
Speaker : Lê Thành Dũng (Tito) Nguyễn (LIS, équipe LSC)
Title : Algorithmique des graphes pour la combinatoire des preuves en logique linéaire
Abstract: Je présenterai comment un lien entre les « réseaux de preuve » de la logique linéaire et les couplages parfaits, découvert par Christian Retoré, peut être exploité pour obtenir des résultats de complexité sur des problèmes qui intéressent les logicien⋅nes. En particulier, ces outils ont mené à la réfutation de l’équivalence entre deux variantes non-commutatives de la logique linéaire (pomset logic et système BV), équivalence qui était conjecturée depuis deux décennies.
https://lmcs.episciences.org/6172
https://lmcs.episciences.org/12705
Juillet 2024 : Intelligence Artificielle – Modèles Algorithmiques
2024/07/18: 9h30
Speaker : Pierre-Henri Wuillemin (LIP6, Sorbonne Université)
Title : Probabilistic Graph Models and Causal models for AI ( Modèles probabilistes graphiques, modèles causaux )
Abstract: La modélisation probabiliste est souvent considéré comme complexe, nécessitant un nombre exponentiel de paramètres, même dans le cas discret. Dans cette présentation, nous nous attacherons à décrire et à motiver les modèles graphiques probabilistes. Après avoir abordé quelques propriétés importantes, nous montrerons en quoi ces mêmes modèles graphiques peuvent servir de support à une analyse quantitative causale, ramenant dans le champs des mathématiques et de la statistique une notion qui a longtemps été considérée pour le moins peu formalisable. (Cette présentation se basera principalement sur les travaux de Judea Pearl, prix Turing 2011)
Pause Cafe : 10:30 — 11:00
11h00
Speaker : Christophe Gonzales (COALA, LIS)
Title : A brief overview of decision under uncertainty
Abstract: Decision under uncertainty is pervasive in artificial intelligence. The goal of this tutorial is to review some popular decision models and highlight their connections as well as the situations in which they can be applied. We will start with the expected utility model (EU) and show the properties it relies on. Then, we will present decision trees, that represent sequential decision problems, and show that the aforementioned properties allow for an efficient algorithm to solve them. Interpreting these trees differently will lead to another more efficient model called an influence diagram. The EU model is known to have severe limitations and, in some situations, more general decision models are needed. Based on a rephrasing of EU, we will present the more general rank dependent utility model (RDU). We will also show the issues of RDU w.r.t. sequential decision making. Another path to generalize EU is to substitute probabilities by other models, notably belief functions. We will show that the EU’s properties presented at the beginning of the talk can also be applied to belief functions, hence resulting in the belief expected utility (BEU) model. We will conclude this talk, mentioning briefly other popular decision models.
March 2024: Algorithmique et Structures Discrètes
2024/03/28: 9h30
Speaker : Pablo Arrighi (LMF, Université Paris-Saclay)
Title : Past, future, what’s the difference?
Abstract: The laws of Physics are time-reversible, making no qualitative distinction between the past and the future—yet we can only go towards the future. This apparent contradiction is known as the ‘arrow of time problem’. Its current resolution states that the future is the direction of increasing entropy. But entropy can only increase towards the future if it was low in the past, and past low entropy is a very strong assumption to make, because low entropy states are rather improbable, non-generic. Recent works from the Physics literature suggest, however, we may do away with this so-called ‘past hypothesis’, in the presence of reversible dynamical laws featuring expansion. We prove that this is the case, for a synchronous graph rewriting-based toy model. It consists in graphs upon which particles circulate and interact according to local reversible rules. Some rules locally shrink or expand the graph. Generic states always expand; entropy always increases—thereby providing a local explanation for the arrow of time. This discrete setting allows us to deploy the full rigour of theoretical Computer Science proof techniques.
Pause Cafe : 10:30 — 11:00
11h00
Speaker : Pierre Ohlmann (MoVe, LIS)
Title : FO-model checking over monadically stable graphs classes
Abstract: In this talk, we will survey recent results (mostly not by me) about efficient model-checking of first-order logic sentences over graphs. We will aim to give a general overview of this very active field, and discuss the different ingredients that come into play. Time allowing, we will go into more details about one of these ingredients: the Flipper game for characterizing monadically stable classes.
February 2024 : Géométrie et Topologie du Calcul
2024/02/01: 9h30
Speaker : Guilherme Dias da Fonseca (LIS)
Title : Shadoks Approach to Convex Covering and Other CG:SHOP Challenges
Abstract: The CG:SHOP Challenge is a geometric optimization challenge organized annually as part of the prestigious SoCG conference. A different problem is proposed each year and the Shadoks team obtained several good results in the last 6 years. We describe these 6 problems, general algorithmic ideas, and strategy used in CG:SHOP 2023. The CG:SHOP 2023 challenge consisted of 206 instances, each being a polygon with holes. The goal was to cover each instance polygon by a small number of convex polygons inside the instance polygon (fewer polygons mean a better score). Our strategy was the following. We find a big collection of large (often maximal) convex polygons inside the instance polygon and then solve several set cover problems to find a small subset of the collection that covers the whole polygon.
( Paper: https://arxiv.org/abs/2303.07696 )
 10h10
Speaker : Bruno Lévy (INRIA, U. Paris-Saclay)
Title : A Lagrangian method for fluids with free boundaries
Abstract: In this presentation, I’ll describe a numerical simulation method for free-surface fluids. I will start by giving an intuitive understanding of the physical phenomena involved in fluid dynamics, pressure, viscosity and surface tension. Then I will detail the numerical simulation method, based on the Gallouet-Mérigot numerical scheme, that describes the fluid as a set of cells, that can deform, but that keep a constant volume, and that follow the motion of the fluid (Lagrangian method). The constant volume constraint takes the form of a partial semi-discrete optimal transport. I will present the geometric and numerical aspects of this optimal transport problem.
The volume conservation constraint takes the form of a partial semi-discrete optimal transport problem. The solution of this transport problem determines the nature of the cells, that correspond to the intersection between Laguerre cells and balls.
( Pause Café : 11:10 – 11:30 )
10h10
Speaker : Bruno Lévy (INRIA, U. Paris-Saclay)
Title : A Lagrangian method for fluids with free boundaries
Abstract: In this presentation, I’ll describe a numerical simulation method for free-surface fluids. I will start by giving an intuitive understanding of the physical phenomena involved in fluid dynamics, pressure, viscosity and surface tension. Then I will detail the numerical simulation method, based on the Gallouet-Mérigot numerical scheme, that describes the fluid as a set of cells, that can deform, but that keep a constant volume, and that follow the motion of the fluid (Lagrangian method). The constant volume constraint takes the form of a partial semi-discrete optimal transport. I will present the geometric and numerical aspects of this optimal transport problem.
The volume conservation constraint takes the form of a partial semi-discrete optimal transport problem. The solution of this transport problem determines the nature of the cells, that correspond to the intersection between Laguerre cells and balls.
( Pause Café : 11:10 – 11:30 )
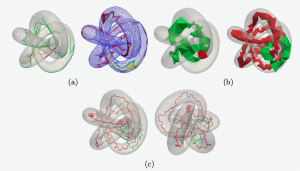 11h30
Speaker : Alexandra Bac (LIS)
Title : Combinatorial duality
Abstract: Alexander duality establishes the relation between the homology of an object and the cohomology of its complement in a sphere. For instance, if X is a subset of the 2-dimensional sphere S2, then each hole of X corresponds to a connected component of S2 \ X, and by symmetry, each hole of S2 \ X corresponds to a connected component of X.
In this work we present a new combinatorial and constructive proof of Alexander duality that provides an explicit isomorphism. The proof shows how to compute this isomorphism using a combinatorial tool called homological colorings. It also provides a one-to-one map between the holes of the object and the holes of its complement, which we use for representing the holes of an object embedded in R3.
11h30
Speaker : Alexandra Bac (LIS)
Title : Combinatorial duality
Abstract: Alexander duality establishes the relation between the homology of an object and the cohomology of its complement in a sphere. For instance, if X is a subset of the 2-dimensional sphere S2, then each hole of X corresponds to a connected component of S2 \ X, and by symmetry, each hole of S2 \ X corresponds to a connected component of X.
In this work we present a new combinatorial and constructive proof of Alexander duality that provides an explicit isomorphism. The proof shows how to compute this isomorphism using a combinatorial tool called homological colorings. It also provides a one-to-one map between the holes of the object and the holes of its complement, which we use for representing the holes of an object embedded in R3.
10h10
Speaker : Bruno Lévy (INRIA, U. Paris-Saclay)
Title : A Lagrangian method for fluids with free boundaries
Abstract: In this presentation, I’ll describe a numerical simulation method for free-surface fluids. I will start by giving an intuitive understanding of the physical phenomena involved in fluid dynamics, pressure, viscosity and surface tension. Then I will detail the numerical simulation method, based on the Gallouet-Mérigot numerical scheme, that describes the fluid as a set of cells, that can deform, but that keep a constant volume, and that follow the motion of the fluid (Lagrangian method). The constant volume constraint takes the form of a partial semi-discrete optimal transport. I will present the geometric and numerical aspects of this optimal transport problem.
The volume conservation constraint takes the form of a partial semi-discrete optimal transport problem. The solution of this transport problem determines the nature of the cells, that correspond to the intersection between Laguerre cells and balls.
( Pause Café : 11:10 – 11:30 )
11h30
Speaker : Alexandra Bac (LIS)
Title : Combinatorial duality
Abstract: Alexander duality establishes the relation between the homology of an object and the cohomology of its complement in a sphere. For instance, if X is a subset of the 2-dimensional sphere S2, then each hole of X corresponds to a connected component of S2 \ X, and by symmetry, each hole of S2 \ X corresponds to a connected component of X.
In this work we present a new combinatorial and constructive proof of Alexander duality that provides an explicit isomorphism. The proof shows how to compute this isomorphism using a combinatorial tool called homological colorings. It also provides a one-to-one map between the holes of the object and the holes of its complement, which we use for representing the holes of an object embedded in R3. Novembre 2023 — Logique et méthodes formelles
Speaker : Nicolas Peltier (CR CNRS, LIG Grenoble)
Title : A proof procedure in separation logic with inductive definitions
Abstract: Separation logic is used in program verification to facilitate reasoning on the dynamically allocated memory. In this talk, I will review recent results concerning the automation of reasoning in Separation logic with inductively defined predicates. In particular I will focus on an inductive proof procedure that is sound, complete and terminating for a fragment of inductive definitions satisfying the so called PCE conditions (Progress, Connectivity, Establishment).
Speaker : Clara Bertolissi (LIS)
Title : Access control policies specification and analysis
Abstract: Access control is a fundamental aspect of computer security; it aims at protecting resources from non-authorised users. The generalised use of access control in modern computing environments has increased the need for high-level declarative languages that enable security administrators to specify a wide range of policy models. In this talk we introduce the main notions of access control and define a declarative meta-model, called CBAC, able to subsume many of the most well known access control models (e.g., MAC, DAC, RBAC). We also design a graphical representation of CBAC policies that aims at easing the specification and verification tasks for security policy administrators. Using such representation of policies, answers to usual administrator queries can be automatically computed, and several properties of access control policies checked.
Speaker : Cameron Calk (Postdoc, LIS)
Title : Coherence via rewriting in higher Kleene algebras
Abstract: Squier’s coherence theorem and its generalisations provide a categorical interpretation of contracting homotopies via confluent and terminating rewriting. In particular, this approach relates standardisation to coherence results in the context of higher dimensional rewriting systems. On the other hand, modal Kleene algebras (MKAs) have provided a description of properties of abstract rewriting systems, and classic (one-dimensional) consistency results have been formalised in this setting.
In this talk, I will recall the notion of higher Kleene algebra, introduced as an extension of MKAs, and which provide a formal setting for reasoning about (higher dimensional) coherence proofs for abstract rewriting systems. First, I will briefly discuss how rewriting techniques are captured in MKAs before showing how these techniques may be extended to higher dimensions.
Juin 2023 — Intelligence Artificielle
Speaker : Liva Ralaivola ( Criteo AI Lab)
Title : Differentially-Private Sliced Wasserstein Distance
Abstract: Developing machine learning methods that are privacy preserving is today a central topic of research, with huge practical impacts. Among the numerous ways to address privacy-preserving learning, we here take the perspective of computing the divergences between distributions under the Differential Privacy (DP) framework — being able to compute divergences between distributions is pivotal for many machine learning problems, such as learning generative models or domain adaptation problems. Instead of resorting to the popular gradient-based sanitiziation method for DP, we tackle the problem at its roots by focusing on the Sliced Wasserstein Distance and seamlessly making it differentially private. Our main contribution is as follows: we analyze the property of adding a Gaussian perturbation to the intrinsic randomized mechanism of the Sliced Wasserstein Distance, and we establish the sensitivity of the resulting differentially private mechanism. One of our important finding is that this DP mechanism transforms the Sliced Wasserstein distance into another distance, that we call the Smoothed Sliced Wasserstein Distance. This new differentially-private distribution distance can be plugged into generative models and domain adaptation algorithms in a tranparent way, and we empirically show that it yields highly competitive performance compared with gradient-based DP approaches from the literature, with almost no loss in accuracy for the domain adaptation problems that we consider. (Joint work with A. Rakotomamonjy, Criteo AI Lab)
Speaker : Van-Giang Trinh (LIS)
Title : Efficient enumeration of fixed points in complex Boolean networks using answer set programming
Abstract:
Boolean Networks (BNs) are an efficient modeling formalism with applications in various research fields such as mathematics, computer science, and more recently systems biology. One crucial problem in the BN research is to enumerate all fixed points, which has been proven crucial in the analysis and control of biological systems. Indeed, in that field, BNs originated from the pioneering work of R. Thomas on gene regulation and from the start were characterized by their asymptotic behavior: complex attractors and fixed points. The former being notably more difficult to compute exactly, and specific to certain biological systems, the computation of stable states (fixed points) has been the standard way to analyze those BNs for years. However, with the increase in model size and complexity of Boolean update functions, the existing methods for this problem show their limitations. To our knowledge, all the state-of-the-art methods for the fixed point enumeration problem rely on Answer Set Programming (ASP). Motivated by these facts, in this work we propose two new efficient ASP-based methods to solve this problem. We evaluate them on both real-world and pseudo-random models, showing that they vastly outperform four state-of-the-art methods as well as can handle very large and complex models.
Avril 2023 — Complexité et Modèles de Calculs
Speaker : Sebastien Tavenas ( LAMA, Université de Savoie Mont-Blanc)
Title : SuperPolynomial lower bounds for circuits of constant depth
Abstract:
Any multivariate polynomial P(X_1,…,X_n) can be written as a sum of monomials, i.e., a sum of products of variables and constants of the field. The natural size of such an expression is the number of monomials. But, what happens if we add a new level of complexity by considering expressions of the form: sum of products of sums (of variables and constants)? Now it becomes less clear how to show that a given polynomial has no small expression. In this talk we will solve exactly this problem. More precisely, we prove that some explicit polynomials do not have polynomial-sized sum-of-products-of-sums (SPS) representations. We can also obtain similar results for SPSPs, SPSPSs, etc. for all expressions of constant depth. We will see also why this problem can be seen an important step for obtaining lower bounds on the size of algebraic circuits.
Speaker : Antonio E. Porreca (CANA, LIS)
Title : The algebra of alternation and synchronisation of finite dynamical systems
Abstract:
Many phenomena of scientific and engineering interest can be modelled as finite dynamical systems, that is, as deterministic transition functions iterated over an abstract set of states. Dynamical systems can be put together (or, from the opposite point of view, analysed) in terms of composition operations, among which two of the most basic ones are alternative and synchronous execution. These give rise to a commutative semiring (a “ring without subtraction”) over dynamical systems up to isomorphism, with some rather complex algebraic properties, notably the lack of unique factorisation into irreducibles. Several interesting decomposition properties can then be expressed in terms of polynomial equations. We discuss computability and complexity issues in solving these equations (most interesting cases are intractable, and the general problem is undecidable), as well as some properties of irreducible systems and the (possible) existence of prime ones.
Février 2023 — Algorithmique et Structures Discrètes
Speaker : Bernadette Charron-Bost ( DIENS )
Title : Distributed Computation of the Average.
Abstract: Computing the average of initial values in a multi-agent system is a fundamental problem in distributed control theory. Unfortunately, an impossibility result by Boldi and Vigna shows that deterministic, anonymous agents communicating by broadcast cannot compute functions dependent on the multiplicity of the input values. In particular, they cannot compute the average of their initial values.
I will first recall the proof developed by Boldi and Vigna using the theory of graph fibrations, and will then review various approaches for circumventing the impossibility result of computing the average. I will notably present a randomized algorithm that computes the average in linear time in the size $n$ of the network, but only with high probability. I will also present a deterministic algorithm, inspired by the popular Metropolis-Hasting method in statistical physics, that computes the average in $O(n^4)$ rounds, under the additional assumption of bidirectional links.
(Joint work with Patrick Lambein-Monette.)
Speaker : Oscar Defrain (LIS – ACRO team)
Title : Minimal dominating sets enumeration in bipartite graphs.
Abstract : Minimal dominating sets enumeration has gained considerable attention since it has been shown equivalent to the long-standing open problem of dualizing a pair of monotone Boolean functions, i.e., deciding whether two positive CNF and DNF are equal. This result, obtained by Kanté, Limouzy, Mary and Nourine in 2014, holds even in the very restricted case of co-bipartite graphs (the vertex set of the graph may be partitioned into two cliques), and was strengthened by a tractable result on split graphs (the vertex set may be partitioned into a clique and an independent set). This has left the case of bipartite graphs (the vertex set may be partitioned into two independent sets) at the center of the attention in the subsequent years. We show it to be tractable inspired by a technique by Eiter, Gottlob and Makino from 2003.
(This is a joint work with Marthe Bonamy, Marc Heinrich, Michał Pilipczuk, and Jean-Florent Raymond.)
Speaker : Pablo Concha Vega (LIS – CANA team)
Title : On the Complexity of Stable and Biased Majority.
Abstract: A majority automata is a two-state cellular automata, where each cell updates its state according to the most represented state in its neighborhood. A question that naturally arises in the study of these dynamical systems asks whether there exists an efficient algorithm that can be implemented in order to compute the state configuration reached by the system at a given time-step. This problem is called the prediction problem. In this work, we study the prediction problem for a more general setting in which the local functions can be different according to their behavior in tie cases. We define two types of local rules: the stable majority and biased majority. The first one remains invariant in tie cases, and the second one takes the value 1. We call this class the heterogeneous majority cellular automata (HMCA). For this latter class, we prove that in two or more dimensions, the problem is P-Complete as a consequence of the capability of the system of simulating Boolean circuits.